One assistant per knowledge area
Create focused assistants for HR, IT support, Linux documentation, networking notes, security procedures or internal company policies. Each assistant can have its own documents, model and retrieval settings.
Private AI · Internal teams · Source-grounded answers
RAGnar is a private AI knowledge system for teams that need quick, reliable answers from their own documentation. It turns internal PDFs, procedures, technical notes and policies into focused AI assistants that can answer questions and show the exact sources behind the response.
It is built for the kind of knowledge work that usually gets stuck in shared folders, old manuals, email threads and repeated questions. Less searching. Less guessing. More useful answers.
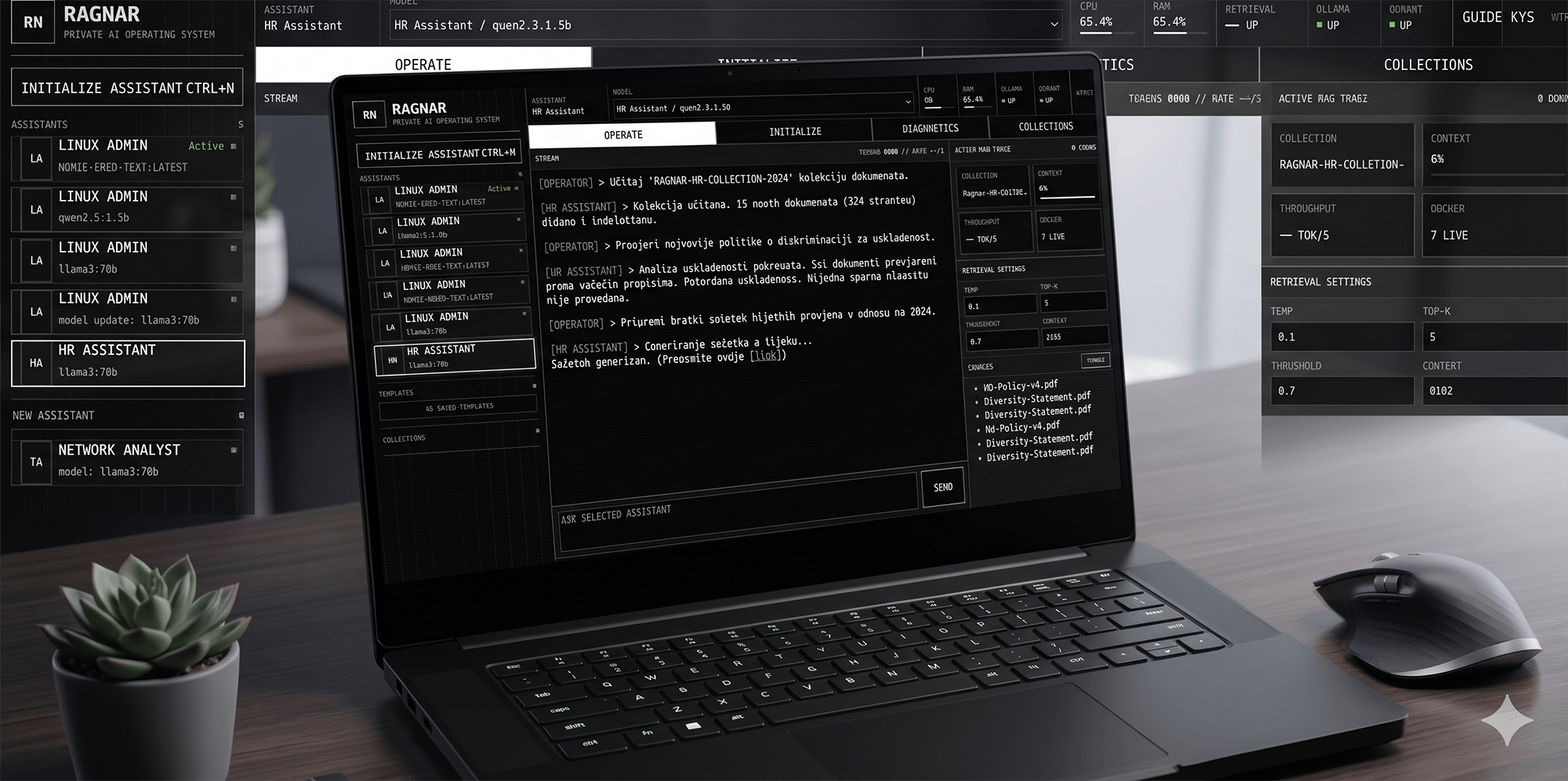
Product
Most teams already have the information they need. The problem is that it is scattered across PDFs, onboarding guides, internal policies, technical manuals and notes that nobody wants to search through. RAGnar gives that knowledge a usable interface: ask a question, get a clear answer, and verify the source.
Create focused assistants for HR, IT support, Linux documentation, networking notes, security procedures or internal company policies. Each assistant can have its own documents, model and retrieval settings.
RAGnar can show document names, source snippets, chunk references and similarity scores. That makes the system easier to trust, easier to test and easier to improve.
The console exposes the settings that actually matter: chunk size, top-k, context window, temperature, similarity threshold, active collection and retrieval trace.
RAGnar Knowledge Processor
Uploading a large PDF into an AI tool is rarely enough. Long documents often create noisy chunks, weak search results and answers that sound confident but miss the right source. RAGnar Knowledge Processor handles the preparation step before documents enter the vector database.
It converts PDF and DOCX content into smaller, cleaner Markdown knowledge files. That gives the assistant better input: clearer sections, more focused chunks and documentation that small local models can use more accurately.
Read text from PDF and DOCX documents and remove obvious layout noise, repeated fragments and formatting leftovers.
Detect headings, sections, lists and topic boundaries so the content is no longer treated as one long block of text.
Write smaller Markdown files by topic, procedure or section, prepared specifically for RAG ingestion.
Send the cleaned knowledge files into the assistant collection, where they become searchable through embeddings and vector search.
Interface
RAGnar is designed to feel more like an operator console than a generic chatbot skin. The interface shows the system behind the answer: assistants, models, retrieval settings, active collections, service status and source traces.
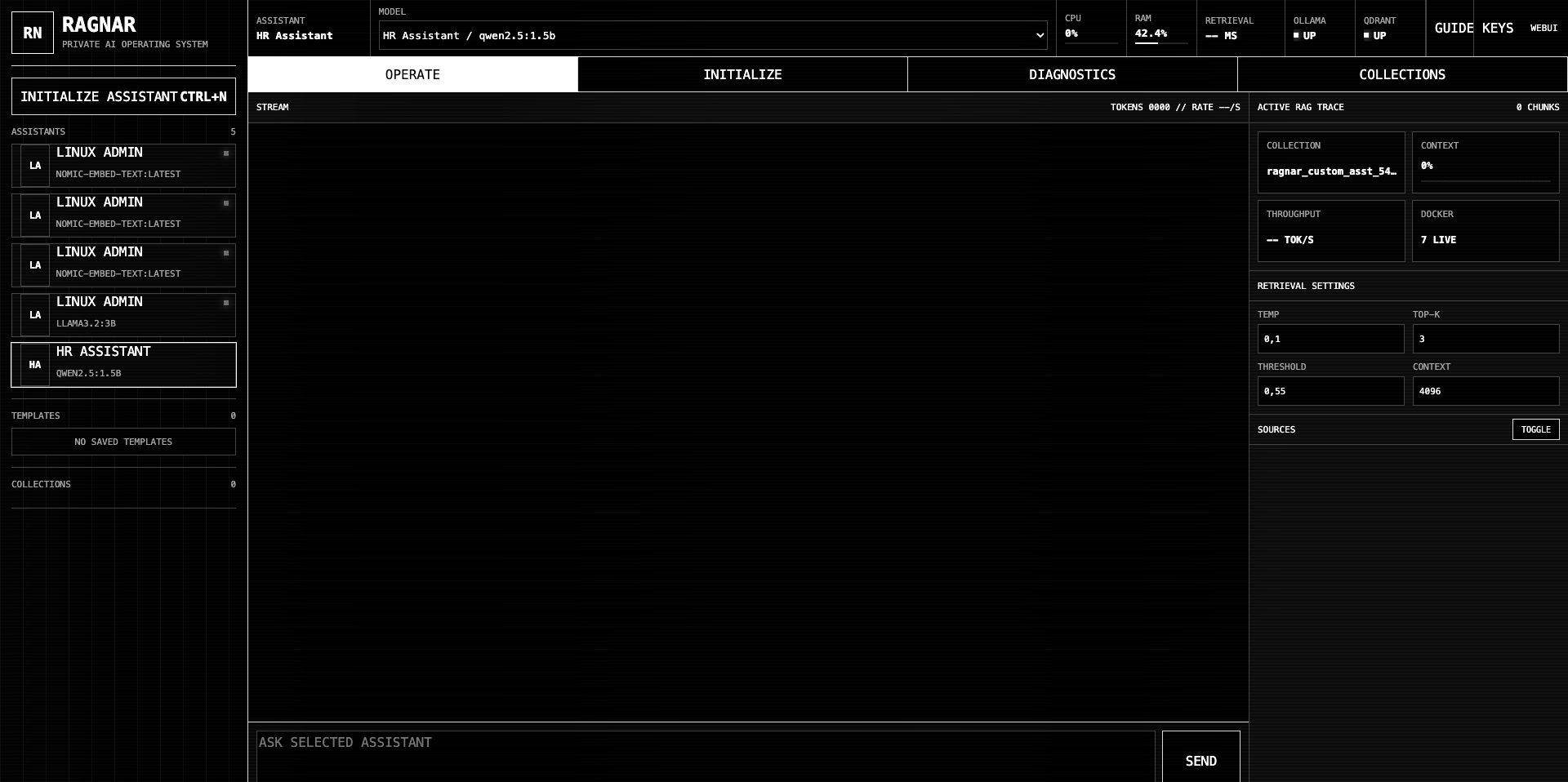
The console helps debug and improve assistant behavior by showing the active model, retrieval threshold, top-k, context length, collection state and source area. This is especially useful when working with smaller local models.
“AI is more useful when it can show its work.”Product principle
Stack
RAGnar combines a familiar AI chat experience with a custom backend, vector database, document processor and local model runtime. It is not just a front-end mockup — the architecture is designed around ingestion, retrieval, citations and operational visibility.
Open WebUI provides the chat foundation, while the RAGnar console adds a focused control layer for assistant setup, diagnostics and retrieval transparency.
Ollama runs local models, while Qdrant stores vector embeddings and powers semantic search across the assistant’s knowledge base.
FastAPI handles the custom API layer, Python powers document preparation, Docker Compose keeps services reproducible and NGINX routes the platform cleanly.
Use cases
RAGnar is a strong fit for organizations with a lot of internal documentation but no simple way to use it day to day: HR procedures, onboarding guides, IT manuals, security policies, training material, support notes and operational knowledge.
The value is not in replacing people. The value is in giving people a faster first answer, a clearer source and a better path to the right procedure.